Hive
1. Hive入门
1.1 什么是Hive
Hive:由Facebook开源用于解决海量结构化日志的数据统计。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将HQL转化成MapReduce程序
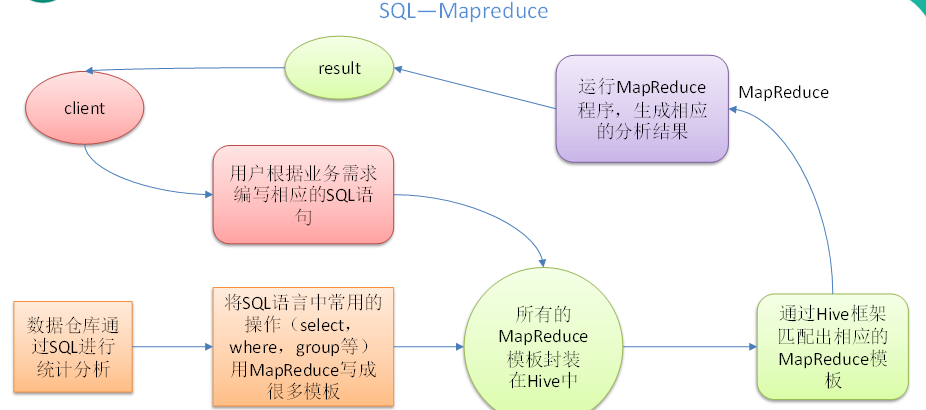
1)Hive处理的数据存储在HDFS
2)Hive分析数据底层的实现是MapReduce
3)执行程序运行在Yarn上
1.2 Hive的优缺点
1.2.1 优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
- 避免了去写MapReduce,减少开发人员的学习成本。
- Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
1.2.2 缺点
1.Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长
2.Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
1.3Hive架构原理
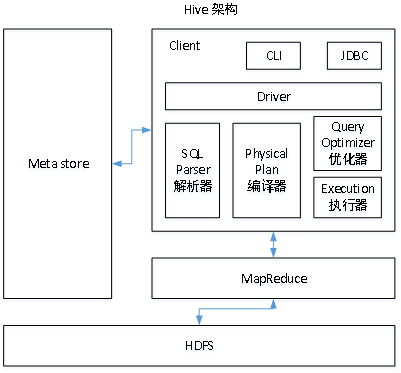
1.用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
2.元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3.Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
4.驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
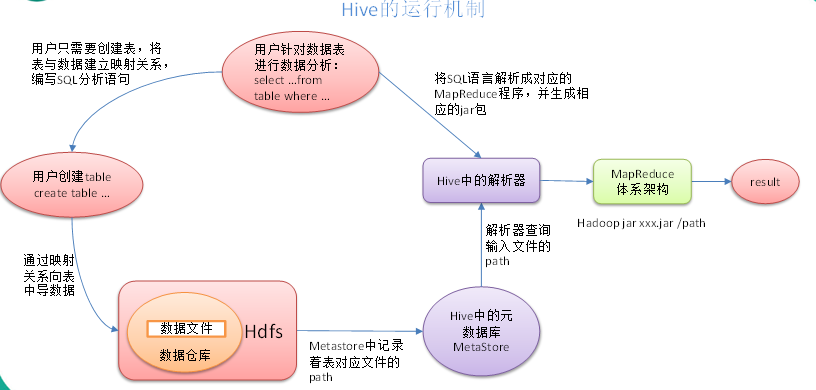
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
2. Hive组件快速安装配置
实验环境:
| 容器系统 | 容器主机名 | 容器ip | 容器用户名 |
|---|---|---|---|
| centos7 | master | 192.168.1.10 | root |
| centos7 | slave1 | 192.168.1.20 | root |
| centos7 | slave2 | 192.168.1.30 | root |
组件版本
| 组件 | 版本 |
|---|---|
| java | 1.8 |
| Hadoop | 3.1.3 |
| Hive | 3.1.2 |
| Mysql | 5.7 |
数据库信息
| 数据库 | 用户名 | 密码 |
|---|---|---|
| mysql | root | 123456 |
2.1 mysql部署
2.1.1 rpm方式部署
(1) 进入mysql资源文件夹,加载所有安装包:
rpm -Uvh *.rpm --nodeps --force结果:
(2) 查看安装情况:
rpm -qa|grep mysql结果: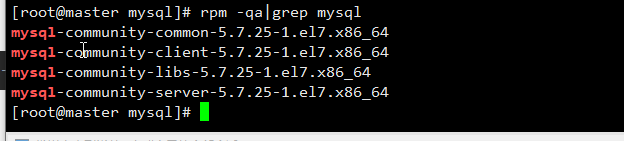
(3) 数据库初始化:
mysqld --initialize --user=mysql(4) 查看临时产生的root用户密码:
grep 'temporary password' /var/log/mysqld.log
(5) 启动Mysql服务,然后登陆数据库,输入临时密码
启动:
[root@master mysql]# systemctl start mysqld
[root@master mysql]# systemctl status mysqld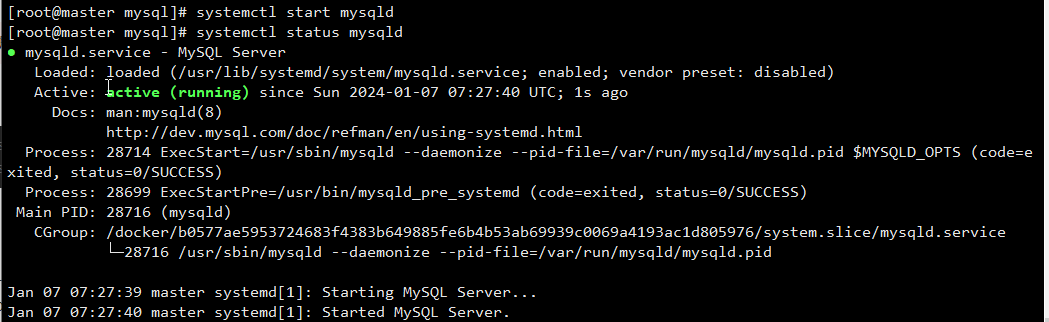
登录数据库:
[root@master mysql]# mysql -uroot -p'zDfW:um0hgdi'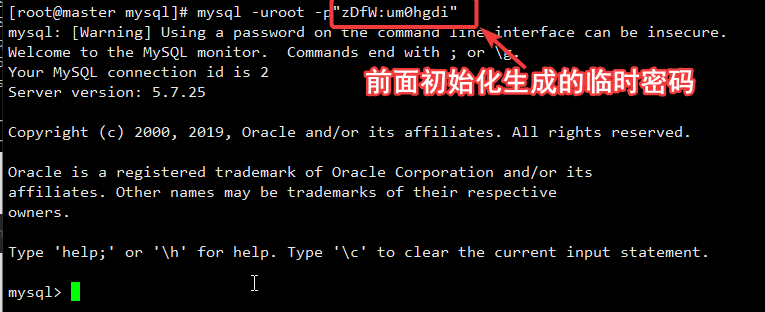
(6) 修改root用户密码
mysql> set password ="123456";
Query OK, 0 rows affected (0.00 sec)(7) 修改MySQL库下的user表中的root用户允许任意ip连接:
方法1:
mysql> grant all privileges on *.* to 'root'@'%' identified by '123456';
mysql> flush privileges; #刷新MySQL的系统权限相关表,否则会拒绝访问方法2:
查看 MySQL 数据库中存在的用户及其允许连接的主机:
==(修改后一定要刷新权限表)==
#可以看出root用户只允许本地连接
mysql> select user,host from mysql.user;
+---------------+-----------+
| user | host |
+---------------+-----------+
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+---------------+-----------+
3 rows in set (0.00 sec)修改root用户允许任意ip连接:
mysql> UPDATE mysql.user SET host = '%' WHERE user = 'root';
mysql> flush privileges;再次查看用户信息:
mysql> select user,host from mysql.user;
+---------------+-----------+
| user | host |
+---------------+-----------+
| root | % |
| mysql.session | localhost |
| mysql.sys | localhost |
+---------------+-----------+
3 rows in set (0.00 sec)修改成功
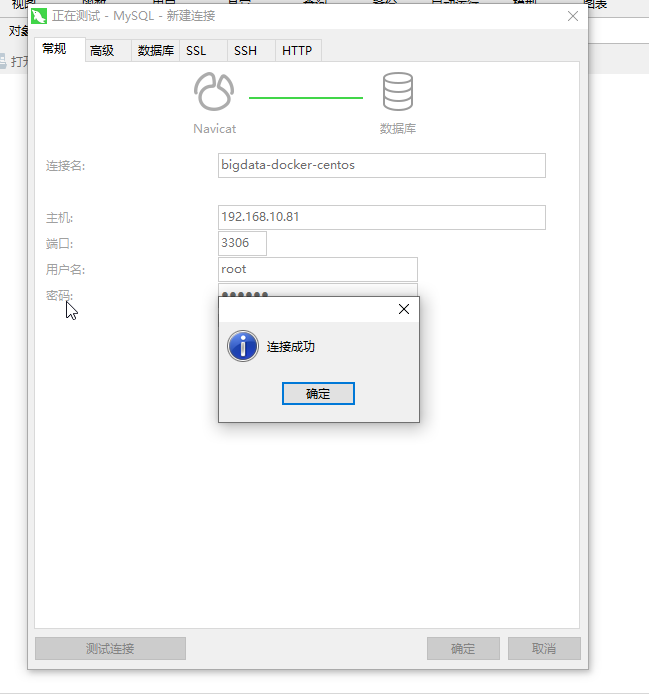
测试远程连接:
(如果是docker部署,记得开放端口)
:warning::warning::warning:可能会遇到的问题:
问题1:在配置Mysql时候,需要授权出现密码不满足当前政策要求(密码安全等级)
首先查看一下密码安全设置:
SHOW VARIABLES LIKE 'validate_password%';如果不是最低权限,设置为最低权限:
set global validate_password_policy=LOW; \\等级
set global validate_password_length=6; \\长度
mysql> flush privileges; #刷新MySQL的系统权限相关表,否则会拒绝访问重新授权:
mysql> grant all privileges on *.* to 'root'@'%' identified by '123456';
mysql> flush privileges; #刷新MySQL的系统权限相关表,否则会拒绝访问问题2: mysql安装失败:
卸载MySQL:
yum remove mysql* -y删除MySQL的安装残留文件
find / -name "mysql*" #查询所有mysql的文件find / -name "*mysql*"|xargs rm -rfv #删除所有查询到的mysql目录,安装包也会被删除清理后重新安装
rpm 常用命令:
1.安装一个包 (展示正在安装的文件信息以及安装进度)
rpm -ivh2.升级一个包
rpm -Uvh3.卸载一个包
rpm -e4.安装参数 –force / -–nodeps
-–force 即使覆盖属于其它包的文件也强迫安装
-–nodeps 如果该RPM包的安装依赖其它包,即使其它包没装,也强迫安装(不检查依赖直接安装)。2.1.2 Docker 一键部署MySQL
(1) 拉取MySQL镜像
[root@bigdata ~]# docker pull mysql/mysql-server:5.7(2) 启动MySQL
docker run -e MYSQL_ROOT_PASSWORD=123456 -e MYSQL_ROOT_HOST=% -p 3306:3306 --name=mysql1 -d mysql/mysql-server:5.7 --character-set-server=utf8mb4参数详解:
docker run: Docker 命令,用于运行一个新的容器。-e MYSQL_ROOT_PASSWORD=123456: 设置 MySQL 根用户的密码为123456。这是通过环境变量设置的。-e MYSQL_ROOT_HOST=%: 允许 MySQL 根用户从任何主机连接。这是通过环境变量设置的,%表示通配符,表示所有主机。-p 3306:3306: 将容器内的 MySQL 端口3306映射到宿主机的端口3307。这是用于让外部应用程序能够连接到 MySQL 服务器。--name=mysql1: 为容器命名为mysql1。-d: 让容器在后台运行(detach 模式)。mysql/mysql-server:5.7: 使用的 MySQL Docker 镜像及其版本。--character-set-server=utf8mb4: 设置 MySQL 服务器的字符集为utf8mb4。
测试:
安装mariadb客户端:
[root@bigdata ~]# yum install mariadb -y使用测试:
[root@bigdata ~]# mysql -uroot -p123456 -h 192.168.10.81 -P 3308 -e "show databases;"
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+MySQL部署完成
2.2 Hive部署
2.2.1 解压并重命名
[root@master ~]# tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
[root@master ~]# mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive2.2.2 添加环境变量
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin#命令行写入环境变量
cat >>/etc/profile<<EOF
#HIVE
export HIVE_HOME=/opt/module/hive
export PATH=\$PATH:\$HIVE_HOME/bin
EOF
#重新载入环境变量
source /etc/profile2.2.3 添加MySQL驱动
将MySQL的JDBC驱动拷贝到Hive的lib目录下:
[root@master ~]# cp /opt/software/mysql/mysql-connector-java-5.1.44-bin.jar $HIVE_HOME/lib查看是否拷贝成功:
[root@master ~]# ll $HIVE_HOME/lib | grep mysql
-rw-r--r-- 1 root root 999635 Jan 7 09:19 mysql-connector-java-5.1.44-bin.jar
-rw-r--r-- 1 root root 10476 Nov 15 2018 mysql-metadata-storage-0.12.0.jar
在HDFS中的user新建hive目录(Hive的数据表实际存储在hadoop中,所以需要先在hdfs中配置数据目录):
创建目录:
[root@master ~]# hdfs dfs -mkdir -p /user/hive/warehouse
查看是否创建成功:
[root@master ~]# hdfs dfs -ls /user/hive
Found 1 items
drwxr-xr-x - root supergroup 0 2024-01-07 09:23 /user/hive/warehouse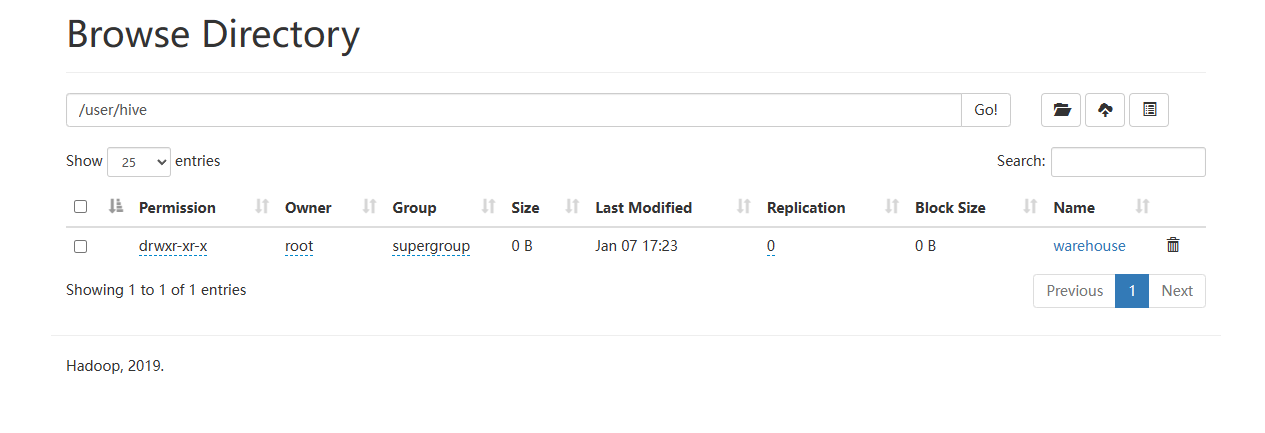
2.2.4 解决guava版本问题(高版本替换低版本)
1.删除旧的guava-19.0.jar,将hadoop中的guava-27.0-jre.jar拷贝过来
[root@master ~]# rm -rf $HIVE_HOME/lib/guava-19.0.jar
[root@master ~]# cp $HADOOP_HOME/share/hadoop/common/lib/guava-27.0-jre.jar $HIVE_HOME/lib
2.查看是否拷贝成功
[root@master ~]# ll $HIVE_HOME/lib/guava-27.0-jre.jar
-rw-r--r-- 1 root root 2747878 Jan 7 09:27 /opt/module/hive/lib/guava-27.0-jre.jar2.2.5 配置hive-site.xml配置文件
方式1:直接修改官方模板
==测试环境部署(方便测试)==
[root@master ~]# cd $HIVE_HOME/conf
[root@master conf]# cp hive-default.xml.template hive-site.xml
[root@master conf]# vi hive-site.xml需要修改的配置位置如下:
568 <name>javax.jdo.option.ConnectionPassword</name>
569 <value>123456</value>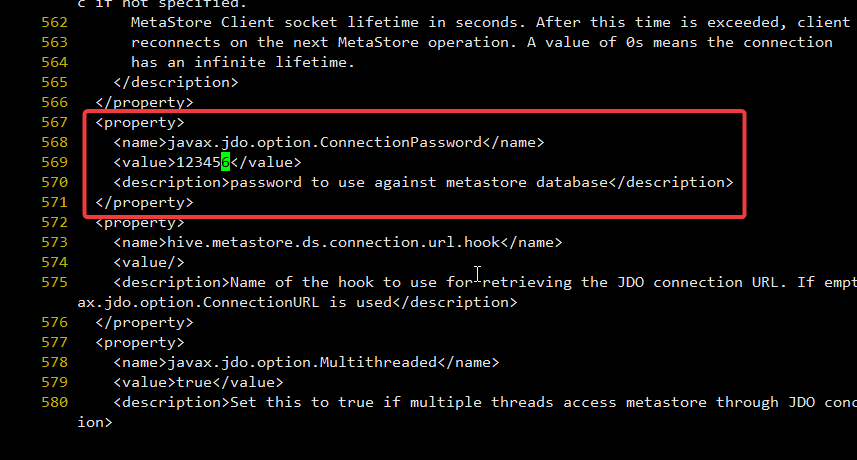
583 <name>javax.jdo.option.ConnectionURL</name>
584 <value>jdbc:mysql://192.168.1.10:3306/metastore?createDatabaseIfNotExist=true&useSSL=false</value>
连接参数:
jdbc:mysql://192.168.1.10:3306/metastore?createDatabaseIfNotExist=true&useSSL=false
&转义字符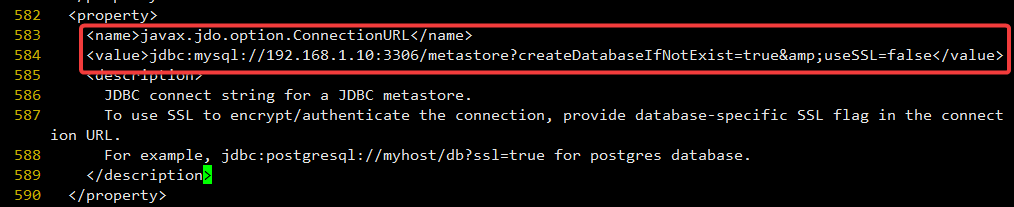
参数解释:
jdbc:mysql://: 指定 JDBC 驱动程序类型,这里是 MySQL 的 JDBC 驱动。192.168.1.10: 数据库服务器的 IP 地址或主机名。3306: MySQL 服务器的端口号,默认是3306。metastore: 数据库的名称(也称为数据库实例)。?createDatabaseIfNotExist=true: 如果数据库不存在,则创建数据库。这是一个额外的参数,用于在连接时创建数据库。&: 这是 HTML 实体编码中的&符号,用于分隔不同的连接参数。useSSL=false: 禁用 SSL 连接,可以提高连接性能。
综合起来,这个连接字符串表示你要连接到位于 192.168.1.10 主机上,端口为 3306 的 MySQL 数据库,数据库名称为 metastore。如果数据库不存在,它将尝试创建一个新的数据库。同时,它禁用了 SSL 连接。
1101 <name>javax.jdo.option.ConnectionDriverName</name>
1102 <value>com.mysql.jdbc.Driver</value>
1126 <name>javax.jdo.option.ConnectionUserName</name>
1127 <value>root</value>
修改数据路径,在配置文件中修改所有的数据路径 4404
所有${system:java.io.tmpdir}/${system:user.name}
改成/home/hive/tmp/root
shift+:进入末行模式
: %s@${system:user.name}@root@g
: %s@${system:java.io.tmpdir}@/home/hive/tmp@g删掉非法字符: 3215行

完成!
方式2:手动编写配置
==生产环境推荐(文档下面的新增配置都是以此配置为基础)==
配置如下:
vi $HIVE_HOME/conf/hive-site.xml<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<!--连接数据库URL-->
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.10:3306/metastore?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<!--连接数据驱动-->
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<!--数据库连接用户名 jdbc 连接的 username-->
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<!--数据库连接密码 jdbc 连接的 password-->
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<!-- Hive 元数据存储版本的验证 -->
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<!-- 元数据存储授权 -->
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<!--本机表的默认位置的URI Hive 默认在 HDFS 的工作目录-->
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>2.2.6 编辑hive-env.sh配置文件
[root@master conf]# cp hive-env.sh.template hive-env.sh
[root@master conf]# vi hive-env.sh添加以下配置(告诉hive Hadoop在哪里):
export HADOOP_HOME=/opt/module/hadoop2.2.7 初始化HIVE元数据库
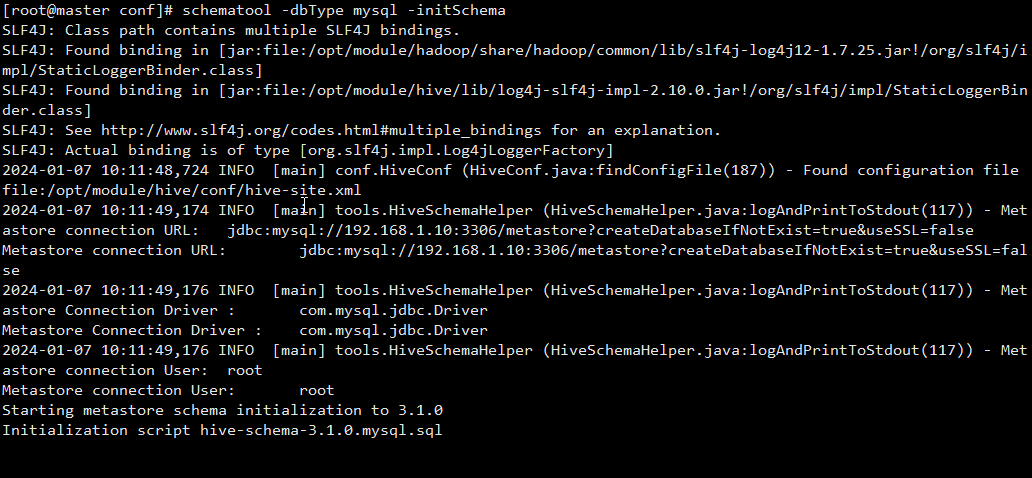
将hive写入mysql
[root@master hive]# schematool -dbType mysql -initSchema 结果如下为成功:

竞赛使用:
schematool -dbType mysql -initSchema > hive.log2.2.8 查询数据库
[root@master conf]# hive -e "show databases;"
发现hive shell中有许多日志信息的解决办法(hive-3.1.2)
解决:
需要在hive的安装目录下:/opt/module/hive/conf/ 创建log4j.properties日志的配置文件,然后写入以下信息就可以了:
方式1:
vi /opt/module/hive/conf/log4j.properties
方式2:
vi $HIVE_HOME/conf/log4j.properties添加以下内容:
log4j.rootLogger=WARN, CA
log4j.appender.CA=org.apache.log4j.ConsoleAppender
log4j.appender.CA.layout=org.apache.log4j.PatternLayout
log4j.appender.CA.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n添加好后保存退出,重启hive即可解决
重新查询数据库:
[root@master ~]# hive -e "show databases;"
2.3 Hive 生产环境部署
2.3.1 Hiveserver2 服务
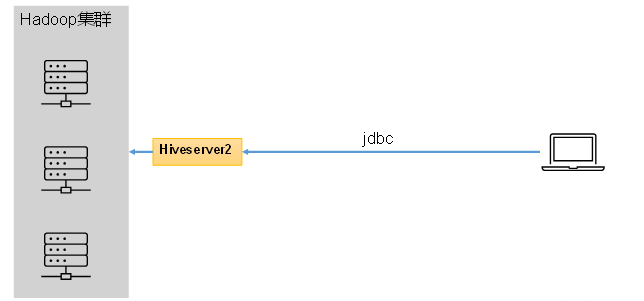
Hive的hiveserver2服务的作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到Hiveserver2。
(1)用户说明
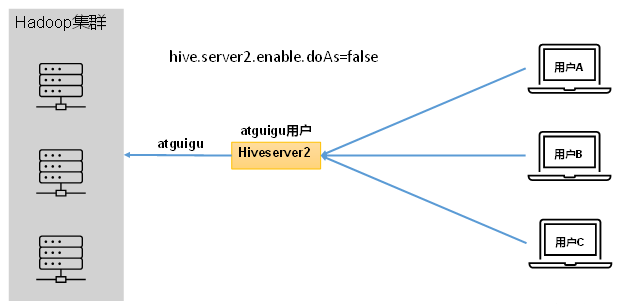
在远程访问Hive数据时,客户端并未直接访问Hadoop集群,而是由Hivesever2代理访问。由于Hadoop集群中的数据具备访问权限控制,所以此时需考虑一个问题:那就是访问Hadoop集群的用户身份是谁?是Hiveserver2的启动用户?还是客户端的登录用户?
答案是都有可能,具体是谁,由Hiveserver2的hive.server2.enable.doAs参数决定,该参数的含义是是否启用Hiveserver2用户模拟的功能。若启用,则Hiveserver2会模拟成客户端的登录用户去访问Hadoop集群的数据,不启用,则Hivesever2会直接使用启动用户访问Hadoop集群数据。模拟用户的功能,默认是开启的。
具体逻辑如下:
:one: 未开启用户模拟功能:
:two:开启用户模拟功能:
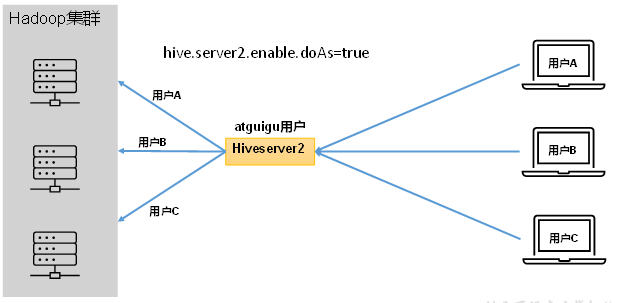
生产环境,推荐开启用户模拟功能,因为开启后才能保证各用户之间的权限隔离。
(2) Hiveserver2部署
:one:Hadoop端配置
hivesever2的模拟用户功能,依赖于Hadoop提供的proxy user(代理用户功能),只有Hadoop中的代理用户才能模拟其他用户的身份访问Hadoop集群。因此,需要将hiveserver2的启动用户设置为Hadoop的代理用户,配置方式如下:
修改配置文件core-site.xml,然后记得分发三台机器,然后再重启hadoop服务
vim $HADOOP_HOME/etc/hadoop/core-site.xml- 增加如下配置:
<!--配置所有节点的root用户都可作为代理用户-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!--配置root用户能够代理的用户组为任意组-->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!--配置root用户能够代理的用户为任意用户-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>:two:Hive端配置
- 在 hive-site.xml 文件中添加以下配置信息
[root@master ~]# vim $HIVE_HOME/conf/hive-site.xml <property>
<!--指定 hiveserver2 连接的 host (使用主机名需要添加本地映射)-->
<name>hive.server2.thrift.bind.host</name>
<value>192.168.1.10</value>
</property>
<property>
<!-- 指定 hiveserver2 连接的端口号 -->
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>:three:测试
- 启动hiveserver2
[root@master ~]# hive --service hiveserver2
查看端口是否已经存在,存在则成功启动hiveserver2
[root@master ~]# ss -tunlp |grep 10000
tcp LISTEN 0 50 *:10000 *:* users:(("java",pid=9885,fd=511))
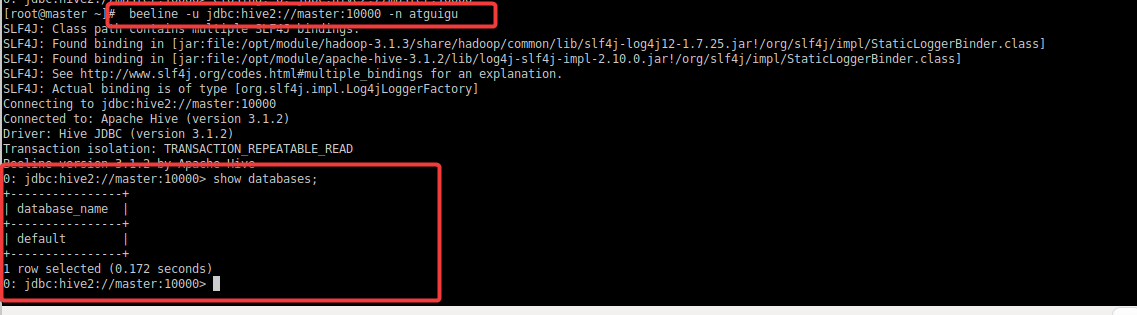
- 新打开一个终端,使用命令行客户端beeline进行远程访问
beeline -u jdbc:hive2://master:10000 -n atguigubeeline:用于与Hive进行交互的命令行工具。-u jdbc:hive2://master:10000:指定JDBC连接URL,其中master是Hive服务器的主机名,10000是端口号。-n atguigu:指定连接时使用的Hive用户名(atguigu)。
或
beeline -u jdbc:hive2://master:10000-u标志用于指定JDBC连接URL,为Beeline提供连接到Hive服务器所需的信息。
结果如下:

- 使用Datagrip图形化客户端进行远程访问
(1)创建连接:
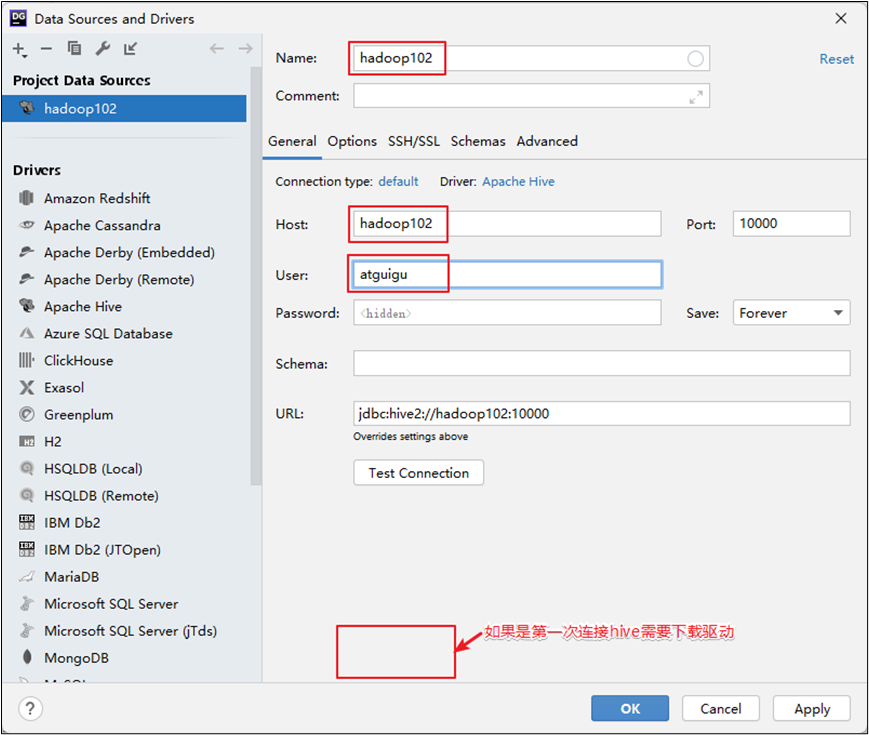
(2)配置连接属性
有属性配置,和Hive的beeline客户端配置一致即可。初次使用,配置过程会提示缺少JDBC驱动,按照提示下载即可
(3)界面介绍
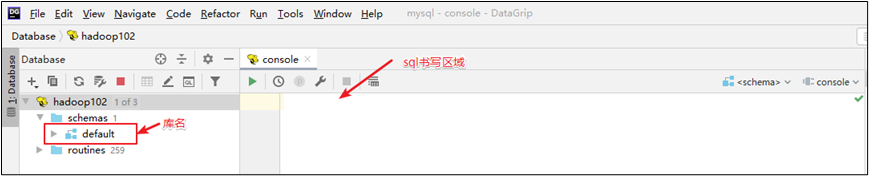
(4)测试sql执行
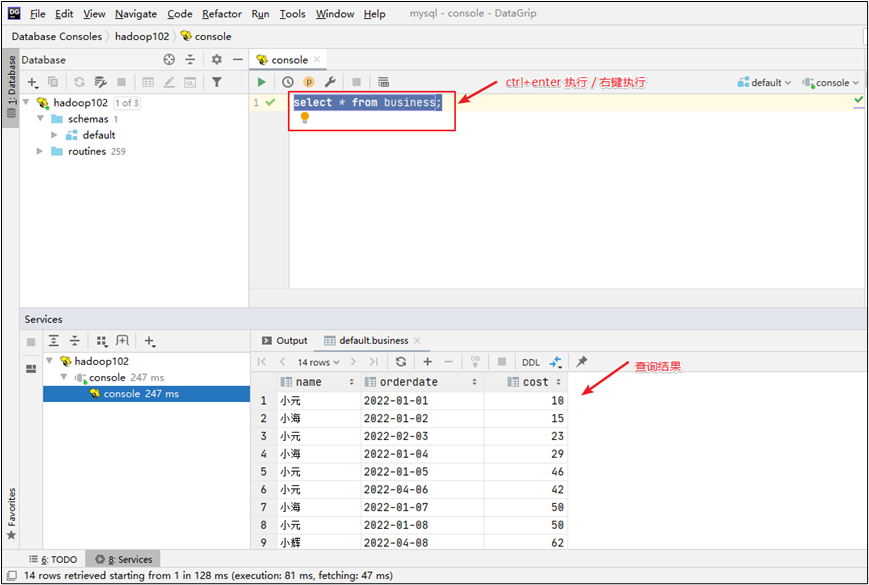
(5)修改数据库
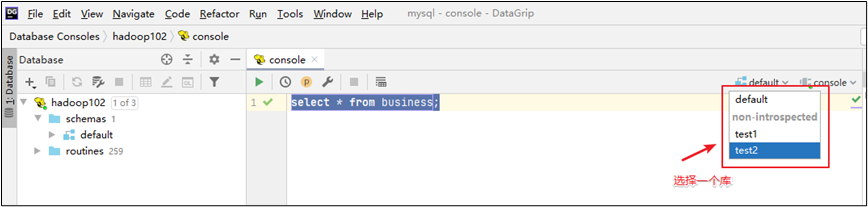
hiveserver2可能出现的报错:(可忽略)
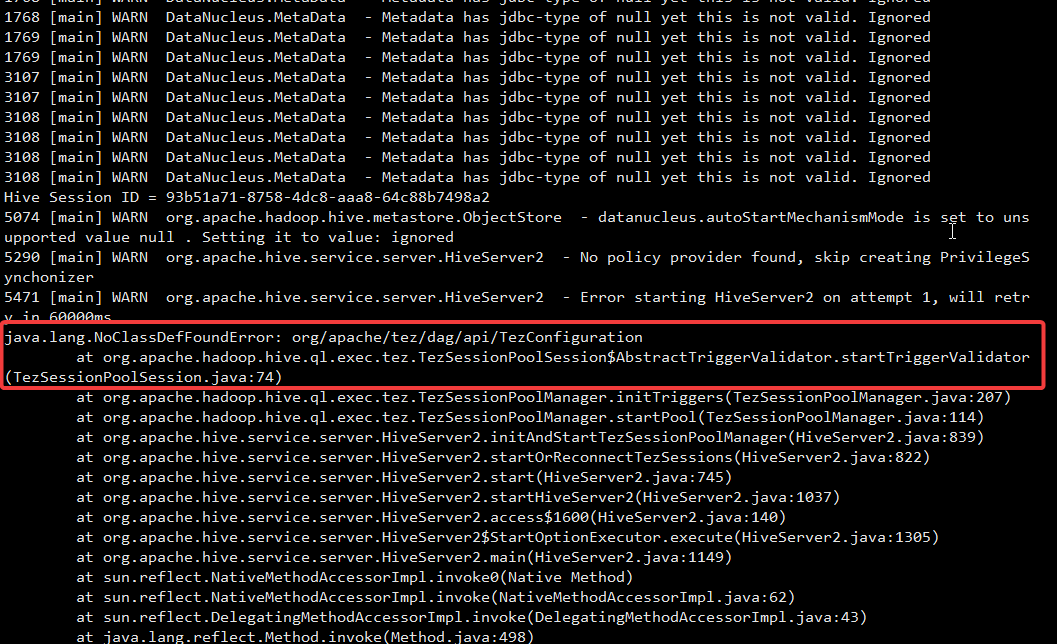
参考: https://www.cnblogs.com/tianlingqun/p/16322927.html
参考添加以下配置
<property>
<!-- 启动hive的高可用性,默认false -->
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>2.3.2 metastore服务
Hive的metastore服务的作用是为Hive CLI或者Hiveserver2提供元数据访问接口。
:one:metastore运行模式
metastore有两种运行模式,分别为嵌入式模式和独立服务模式。下面分别对两种模式进行说明:
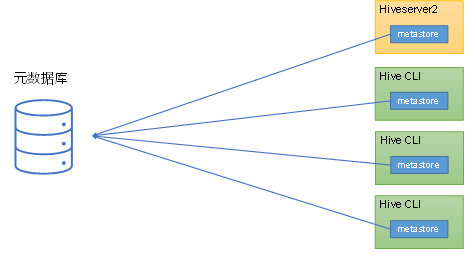
(1)嵌入式模式
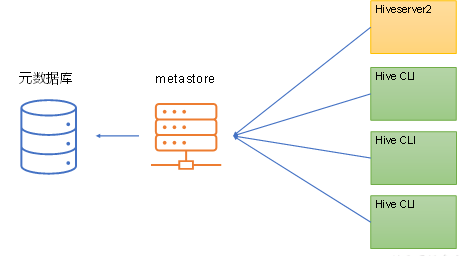
(2)独立服务模式
生产环境中,不推荐使用嵌入式模式。因为其存在以下两个问题:
(1)嵌入式模式下,每个Hive CLI都需要直接连接元数据库,当Hive CLI较多时,数据库压力会比较大。
(2)每个客户端都需要用户元数据库的读写权限,元数据库的安全得不到很好的保证。
:two:metastore部署
(1)嵌入式模式
嵌入式模式下,只需保证Hiveserver2和每个Hive CLI的配置文件hive-site.xml中包含连接元数据库所需要的以下参数即可(前面部署时已添加):
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.10:3306/metastore?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>(2)独立服务模式
独立服务模式需做以下配置:
首先,保证metastore服务的配置文件hive-site.xml中包含连接元数据库所需的以下参数:
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.10:3306/metastore?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>其次,保证Hiveserver2和每个Hive CLI的配置文件hive-site.xml中包含访问metastore服务所需的以下参数:
(添加以下参数)
<!-- 指定metastore服务的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>注意:主机名需要改为metastore服务所在节点,端口号无需修改,metastore服务的默认端口就是9083。
(3) 测试
此时启动Hive CLI,执行shou databases语句,会出现一下错误提示信息:
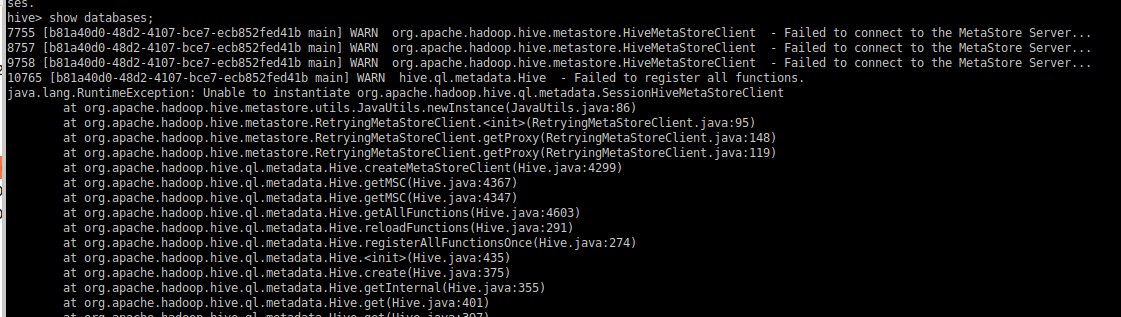
这是因为我们在Hive CLI的配置文件中配置了hive.metastore.uris参数,此时Hive CLI会去请求我们执行的metastore服务地址,所以必须启动metastore服务才能正常使用。
metastore服务的启动命令如下:
hive --service metastore注意:启动后该窗口不能再操作,需打开一个新的Xshell窗口来对Hive操作
新开一个终端,重新启动 Hive CLI,并执行shou databases语句,就能正常访问了:
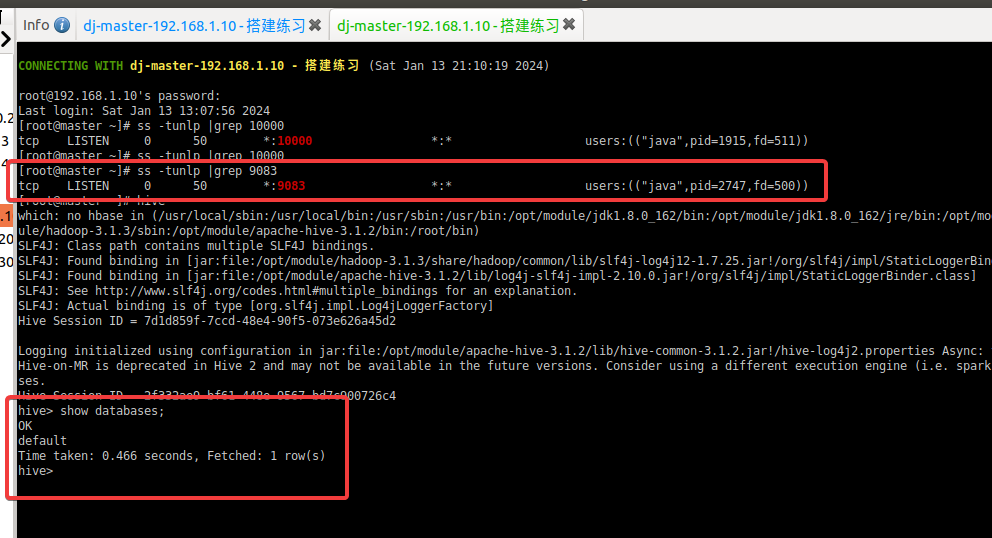
2.3.3 修改hive日志默认路径
需要修改的文件模板如下:
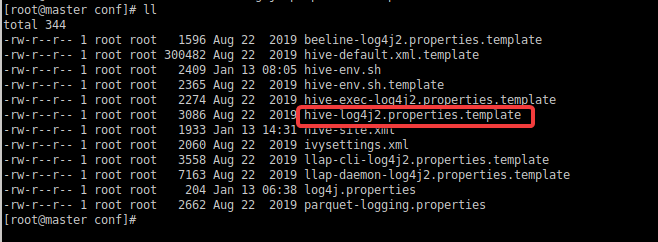
如果初次配置,在conf文件夹下,复制一份模板
[root@master conf]# cp hive-exec-log4j2.properties.template hive-log4j2.properties
[root@master conf]# vim hive-log4j2.properties修改property.hive.log.dirproperty.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name}这个会解析成/tmp/启动hive用户名称/hive.log
配置的时候可以写成绝对路径
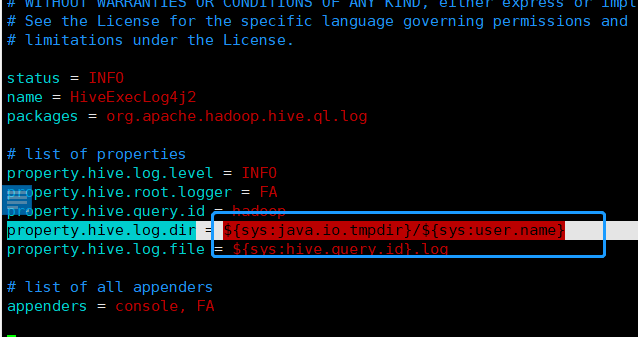
修改结果如下:
# list of properties
property.hive.log.level = INFO
property.hive.root.logger = DRFA
#property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name}
property.hive.log.dir = /opt/module/apache-hive-3.1.2/logs
property.hive.log.file = hive.log
property.hive.perflogger.log.level = INFO2.3.4 编写Hive服务启动脚本
nohup:放在命令开头,表示不挂起,也就是关闭终端进程也继续保持运行状态
/dev/null:是Linux文件系统中的一个文件,被称为黑洞,所有写入该文件的内容都会被自动丢弃
2>&1:表示将错误重定向到标准输出上
&:放在命令结尾,表示后台运行
一般会组合使用:nohup [xxx命令操作]> file 2>&1 &,表示将xxx命令运行的结果输出到file中,并保持命令启动的进程在后台运行。
启动命令如下:
nohup hive --service metastore 2>&1 &
nohup hive --service hiveserver2 2>&1 &添加启动脚本(了解)
1.编辑启动脚本
vi $HIVE_HOME/bin/hiveservices.sh
2.编辑完后添加可执行权限
chmod +x $HIVE_HOME/bin/hiveservices.sh脚本内容如下:
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(ss -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
function hive_status()
{
ss -tunlp | grep 10000 > /dev/null
if [ $? -ne 0 ];then
sleep 3
echo "HiveServer2服务运行异常"
else
sleep 3
echo "HiveServer2服务运行正常"
fi
ss -tunlp | grep 9083 > /dev/null
if [ $? -ne 0 ];then
echo "Metastore服务运行异常"
else
echo "Metastore服务运行正常"
fi
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
# check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
# check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
hive_status
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac脚本启动测试
[root@master ~]# hiveservices.sh start查看端口号是否已启动:
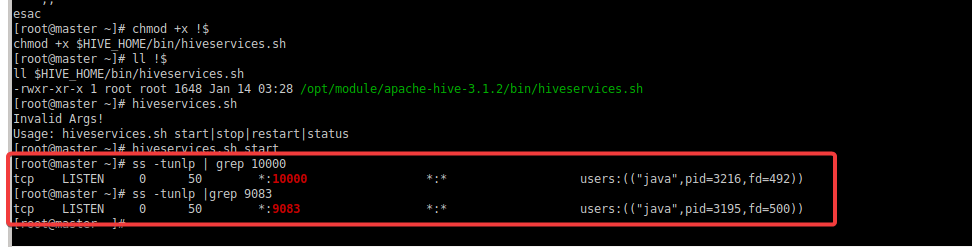
脚本启动成功!
部署完成!!!
2.4 Hive使用技巧
2.4.1 Hive常用交互命令
查看帮助:
[root@master hive]$ bin/hive -help
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the console)例1:
1)在Hive命令行里创建一个表student,并插入1条数据
hive (default)> create table student(id int,name string);
OK
Time taken: 1.291 seconds
hive (default)> insert into table student values(1,"zhangsan");
hive (default)> select * from student;
OK
student.id student.name
1 zhangsan
Time taken: 0.144 seconds, Fetched: 1 row(s)
2)“-e”不进入hive的交互窗口执行hql语句
[root@master hive]$ bin/hive -e "select id from student;"3)“-f”执行脚本中的hql语句
(1)在/opt/module/hive/下创建datas目录并在datas目录下创建hivef.sql文件
[atguigu@master hive]$ mkdir datas
[atguigu@master datas]$ vim hivef.sql
(2)文件中写入正确的hql语句
select * from student;
(3)执行文件中的hql语句
[atguigu@master hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql
(4)执行文件中的hql语句并将结果写入文件中
[atguigu@master hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql > /opt/module/hive/datas/hive_result.txt例2:
create table if not exists orders(
id string,
userno string,
password string,
email string,
phone string,
name string,
idcard string,
status int,
depid string
)
row format delimited fields terminated by ',';
从本地将csv文件导入hive(需要提前建好表):
load data local inpath '文件路径' into table 表名;
load data local inpath '/opt/user.csv' into table orders;将hdfs中的文件导入hive:
load data inpath ‘hdfs中csv文件路径’ into table 表名;
load data inpath '/data081/order.csv' into table orders;导入完成
执行导入语句说明:
load data inpath ‘/tmp/fun_user.txt’ into table fun_user_external;
load data local inpath ‘/tmp/fun_user.txt’ into table fun_user_external;
上面两条数据导入语句,如果有local这个关键字,则这个路径应该为本地文件系统路径,数据会被拷贝到目标位置;如果省略掉local关键字,那么这个路径应该是分布式文件系统中的路径,这种情况下,数据是从这个路径转移到目标位置的。


